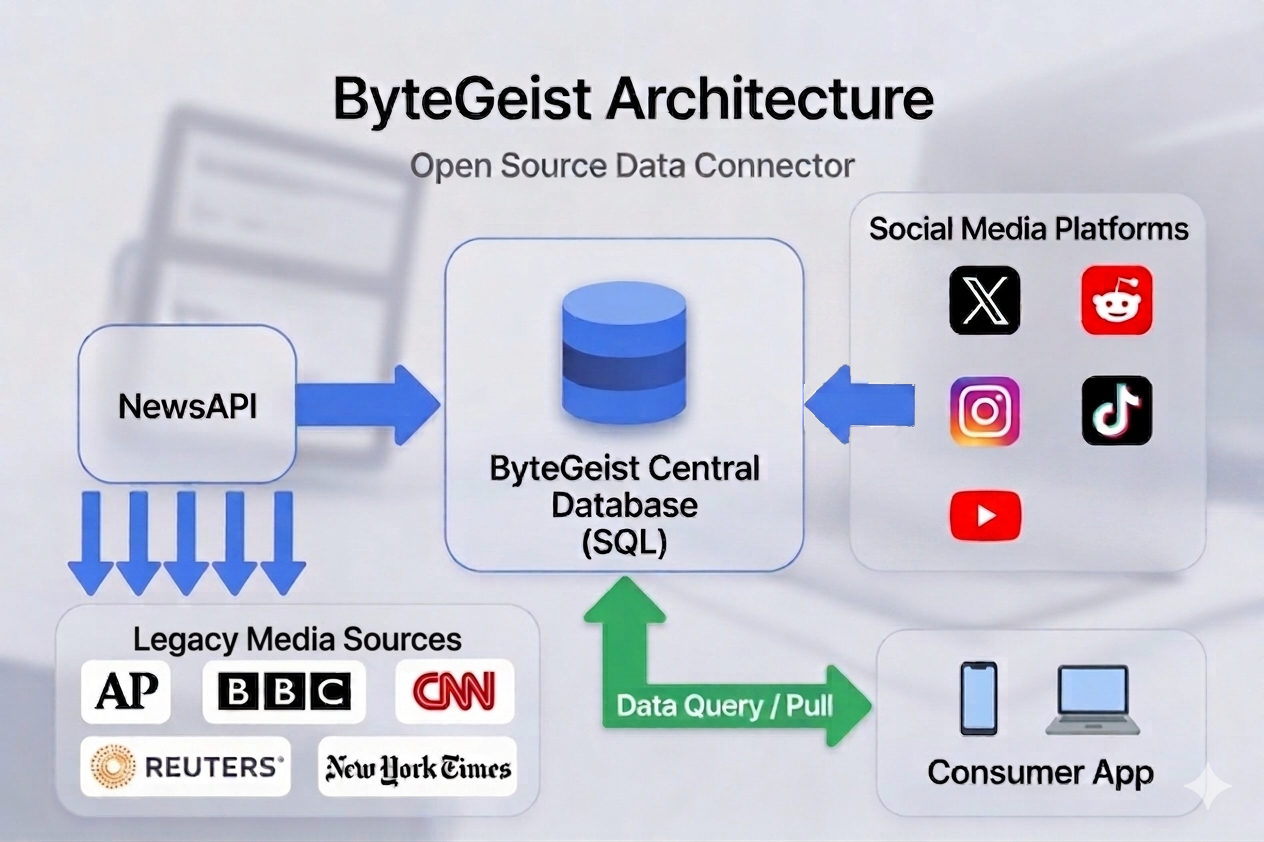
ByteGeist is an open source data aggregation layer designed to serve as a foundation for any application that needs a reliable, daily feed of structured news and social media content. Rather than building scrapers and API integrations from scratch, downstream apps simply connect to ByteGeist's SQL tables and consume clean, ready-to-query data. Data is automatically pulled on a daily basis from 5 legacy media sources (AP, Reuters, BBC, CNN, NYT) and 5 social media platforms (X, Reddit, Instagram, TikTok, YouTube). Sentiment analysis, trend detection, narrative tracking, misinformation research, media bias studies — any application that needs a pulse on what the world is talking about can be built on top of ByteGeist without touching a single API directly. This can be used to build powerful apps that can measure any characteristics of the platforms surveyed, along with how those characteristics change over time, since data is pulled on a daily basis. A few possibilities for apps powered by ByteGeist: 1) How much of the content in legacy and social media is AI generated? 2) How much can be considered propaganda? 3) Is there any correlation between sentiment/emotions in legacy/social media and events like holidays, geopolitical events, or astronomical events? These are just a few examples of what's possible with ByteGeist.
ByteGeist pulls data from two distinct layers of the daily information ecosystem — legacy media and social media — storing everything in normalized SQL tables.
Data Layer
Legacy Media
ByteGeist scrapes world news articles daily from five of the most widely read English-language outlets: AP, Reuters, BBC, CNN, and the New York Times. These five sources collectively account for an estimated 1.2–1.3 billion monthly visits, representing a substantial portion of global English-language news readership. Crucially, AP and Reuters are wire services whose copy is republished by hundreds of downstream outlets — meaning ByteGeist's legacy corpus captures not just direct readership but the upstream source material that shapes coverage across the broader media landscape. Each source's relative readership is stored alongside the article data, enabling downstream apps to apply weighted averages if needed (see market share table below).
Data Layer
Social Media
ByteGeist collects high-engagement, trending content daily from X, Reddit, Instagram, TikTok, and YouTube, storing posts, metadata, and engagement metrics in SQL. Rather than random sampling, ByteGeist targets the influential core — content that is actually reaching and being engaged with by large audiences on a given day. Combined, these five platforms represent approximately 8.5 billion monthly active users globally, though with significant cross-platform overlap. Per-platform data is kept separate in the schema rather than aggregated, since user bases differ significantly in demographic composition and ideological lean — a design decision that gives downstream apps full flexibility in how they weight or combine the data.
System Overview
Architecture
Methodology
Statistical Stuff
For any very large population, such as all the daily posts on a given social platform, ~385 elements (posts) need to be randomly sampled in order to generalize about the entire population with 95% confidence (5% margin of error). The derivation for this is:
n = (z² * p * (1-p)) / e²
n = (1.96² * 0.5 * 0.5) / 0.05²
n = 384.16 ≈ 385
This math is for random sampling. ByteGeist does not use random sampling, rather it scrapes from the influential core - segments that drive the vast majority of statistical change, growth, or behavior. Instead of looking at the population evenly, it isolates the small, high-impact groups that shape the overarching trends (though outliers and fringe views are less likely to be captured). For social platforms, this translates to trending/popular posts, and for legacy media the 5 sources mentioned represent about 20% of total English-news readership, but much higher in terms of influence since AP and Reuters feed hundreds of downstream outlets.
ByteGeist's daily corpus combines ~300 articles from major legacy outlets with ~400 high-engagement social posts across the aforementioned platforms. Together these represent both the institutional narrative and the dominant public reaction — the two most influential layers of the daily information ecosystem. Note that for the social platforms, only top level posts are pulled - not replies. This cuts down on "noise" and allows us to drill down to a clearer picture of the overall "pulse" of these platforms. Call it the daily "zeitgeist" of the internet.
Audience Size
Market Share Reference
Downstream apps can use the following figures to construct weighted averages across sources. ByteGeist stores raw data only — the weighting logic lives in your app, though easy to use functions are provided for this purpose.
Note that cross-platform overlap is substantial — most users are active on multiple platforms. MAU figures represent each platform's individual addressable audience, not a deduplicated global total. For apps that desire to present an overall picture of legacy media vs social media, functions to weight each source according to audience size (above) are provided. This is certainly not required, as it could be valuable to consider sources on their own as well. ByteGeist provides ALL the data for you to use as you wish.
Reference App
Example Application: Sentiment, Emotion & Topic Analysis
The reference implementation included in this repository (coming soon) demonstrates one way to build on ByteGeist's data layer. It queries the daily article and post tables, runs each piece of content through a sentiment/topic analysis model, and produces per-source sentiment and emotion scores alongside a market-share-weighted aggregate — giving a statistically grounded snapshot of how legacy media and social platforms are framing world events on any given day. It also discovers topics that are being most frequently written about. The weighted average methodology, confidence interval calculations, and inter-source agreement metrics are all documented in the example app's source.
This is merely one possible application. The data ByteGeist collects is general-purpose — the SQL schema is intentionally minimal and unopinionated so that whatever you're building, the data fits naturally into your existing pipeline. I am in the process of creating several other apps that use ByteGeist - a couple examples are: 1) What percentage of posts/articles are written by AI? 2) What percentage qualify as propaganda? 3) How do dominant emotions and overall sentiment differ between legacy and social media? 4) An astrology app that measures correlation of sentiment/emotions in legacy/social media with astronomical events (statistically speaking, causation is extremely difficult to prove, so we will focus only on correlation).
Roadmap
What's in v1? What's coming soon?
Platform
Data Pulled
Legacy Media Sources
Text only
YouTube
Video only
Instagram
Images only
TikTok
Video only
Reddit
Text only
X
Text only
As you can see from the table above, v1 focuses on the primary medium used on each platform. v2 is coming soon and will feature all available types of content from each platform.
Get in touch
Contact
Questions, ideas, or building something on ByteGeist? Reach out.